| Table of Contents |
|---|
개념정리
| 개념 | 설명 |
|---|---|
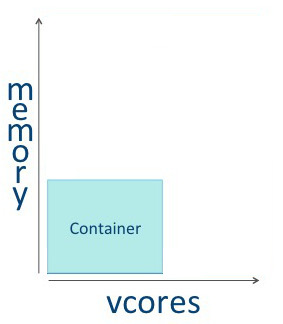
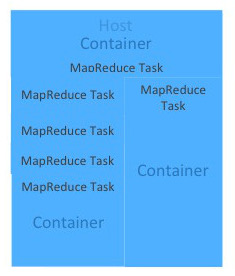
| 각 호스트의 구성 | 각 호스트는 VCore와 Memory 자원을 사용할 수 있음
|
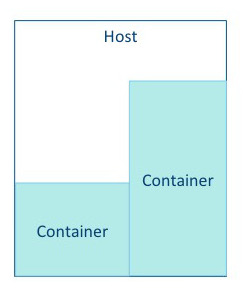
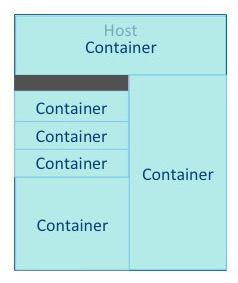
| 컨테이너 | 가용 자원을 바탕으로 컨테이너를 실행시킬 수 있으며 컨테이너는 VCore와 Memory를 할당받아 소비함.
각 호스트에는 다양한 자원을 소비하는 컨테이너를 구동시킬 수 있음. 데이터의 크기와 작업의 워크로드에 따라서 리소스를 배정할 수 있음.
YARN Resource Manager는 Memory와 VCore를 잘 사용할수 있도록 배정하고 관리함
|
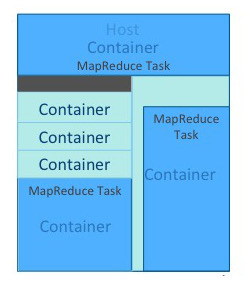
| 애플리케이션 | 애플리케이션이라고 함은 컨테이너에서 동작하는 프로그램을 의미하며 Spark 프로그램일 수도 있고 MapReduce Java 프로그램일 수도이 있음.
YARN은 VCore와 Memory를 효율적으로 사용할수 있도록 컨테이너에 자원을 배정하고 애플리케이션을 실행함.
|
| YARN 아키텍처 |
|
| Hadoop 1 아키텍처 |
|
| Hadoop 2 아키텍처 |
|




YARN VCore 및 Memory 설정
| YARN VCore 및 Memory 설정 | 의미 |
|---|---|
yarn.scheduler.minimum-allocation-mb | 컨테이너에 할당할 수 있는 Memory의 최소 크기 |
yarn.scheduler.maximum-allocation-mb | 컨테이너에 할당할 수 있는 Memory의 최대 크기 |
yarn.scheduler.minimum-allocation-vcores | 각 Node Manager가 컨테이너에 할당할 수 있는 최소 |
| VCore 개수 | |
yarn.scheduler.maximum-allocation-vcores | 각 Node Manager가 컨테이너에 할당할 수 있는 |
...
| 최대 VCore 개수 | |
yarn.nodemanager.resource.cpuvcores | 컨테이너의 VCore 개수 |
yarn.nodemanager.resource.memorymb | 컨테이너의 메모리 |
yarn.app.mapreduce.am.resource.cpuvcores | Application Master의 VCore 개수 |
yarn.app.mapreduce.am.resource.mb | Application Master의 Memory |
mapreduce.map.cpu.vcores | Map Task의 CPU VCore 개수 |
mapreduce.map.memory.mb | Map Task의 Memory |
mapreduce.reduce.cpu.vcores | Reduce Task의 CPU VCore 개수 |
mapreduce.reduce.memory.mb | Reduce Task의 Memory |
mapreduce.task.io.sort.mb | I/O Sort Memory |
YARN Scheduler
Spark의 실행 모드
| 실행 모드 | 개요 |
|---|---|
| Cluster Mode | Spark Driver의 실행 위치가 Client Application이 아닌 YARN의 Container Spark Job의 무수히 많이 실행되는 상황이라면 Client 모드로 Spark Driver를 사용하는 경우 Client를 실행하는 서버는 엄청난 메모리를 소비하게 됨
|
| Client Mode | Spark Driver가 Client Application 쪽에서 실행되는 구조 Scalable 하지 않지만 관리하기가 편리함 많은 Job이 실행되는 상황이라면 Client 모드는 지양해야 함
|
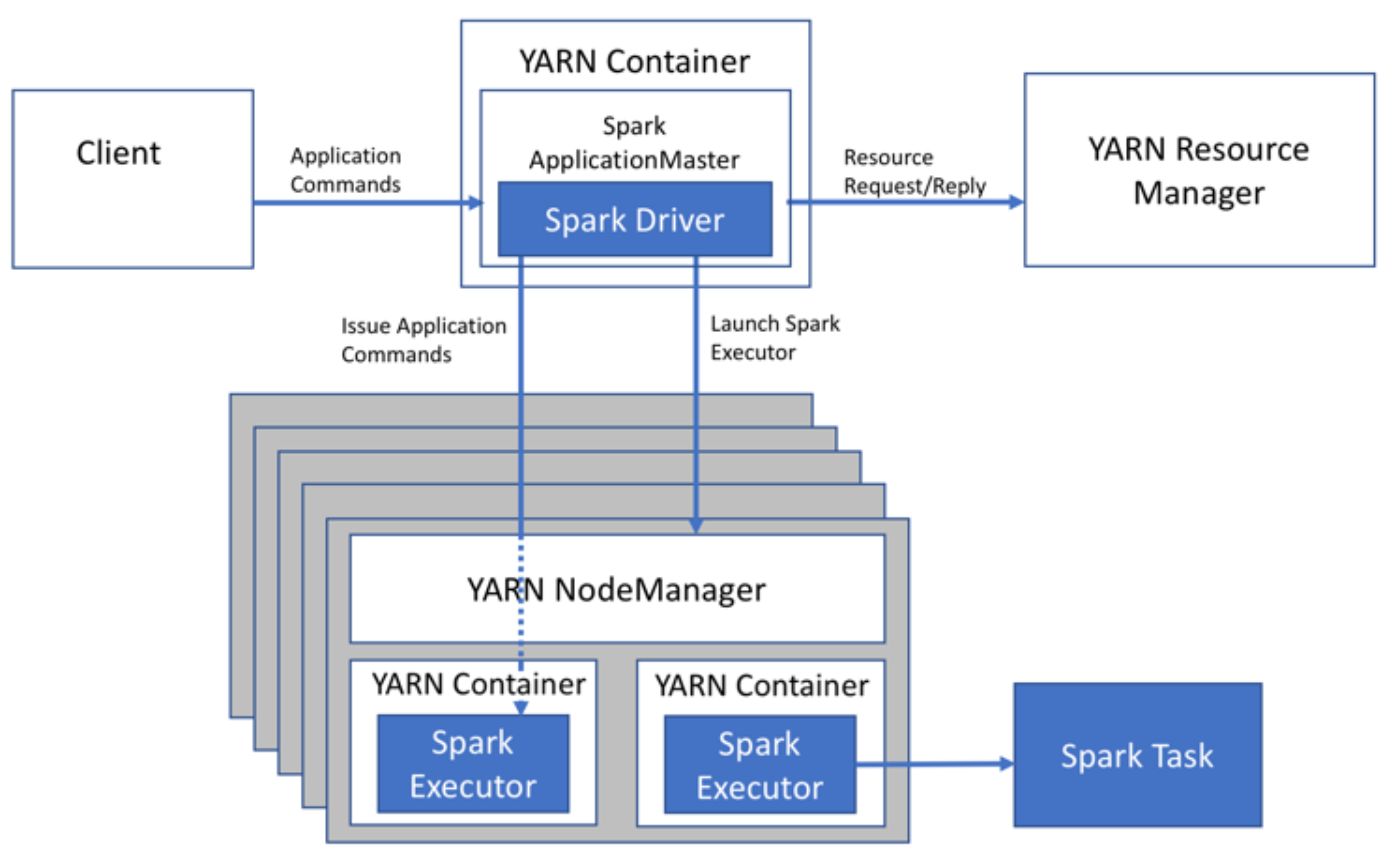
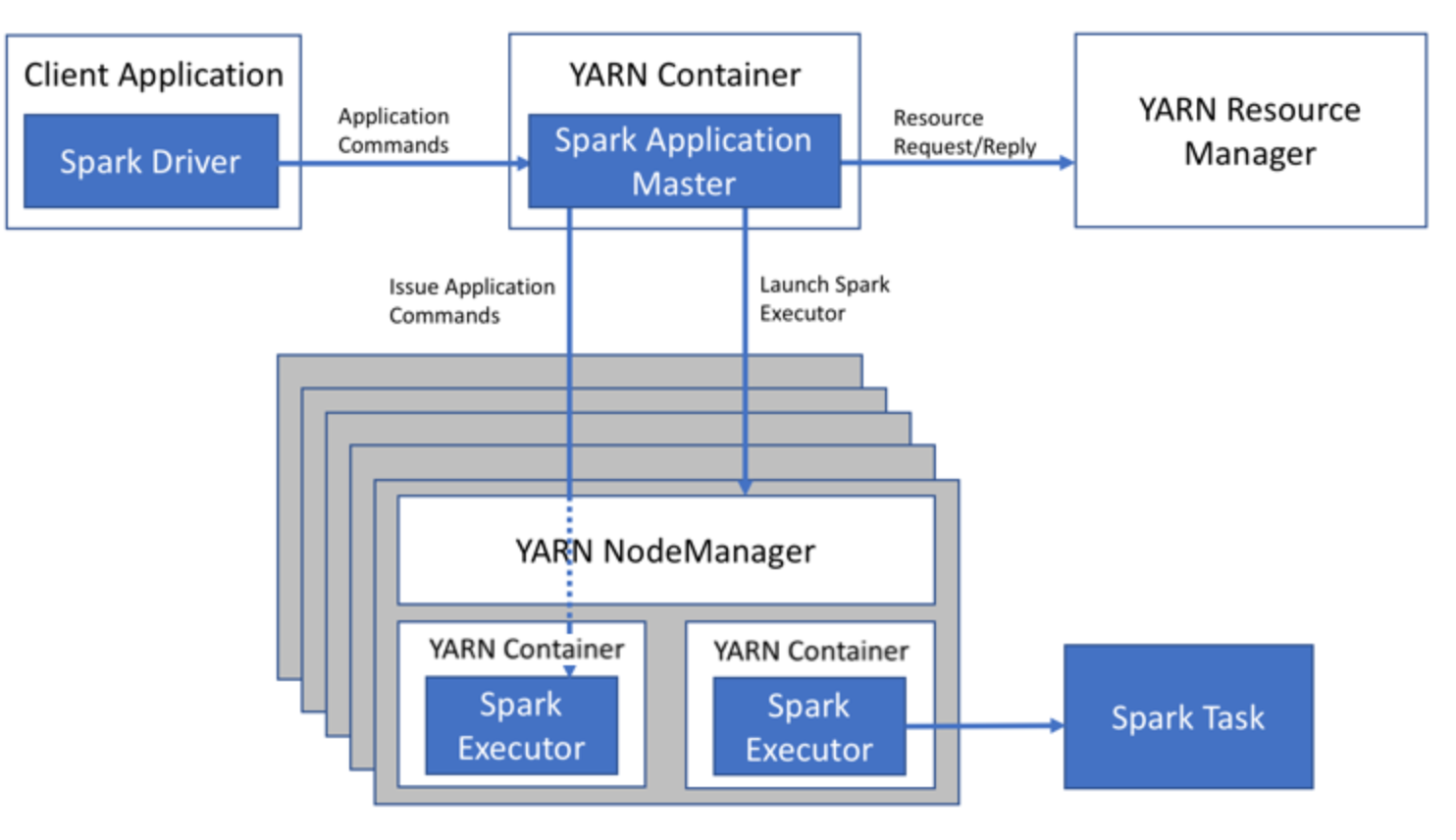
Spark의 아키텍처 기반 튜닝 포인트
- Spark Job의 Spark Driver가 어디에서 실행되는가?
- Executor의 개수는 적절한가
- Executor의 GC가 과도하지 않은가? → 총 실행시간 대비 GC의 시간은?
- 셔플링을 얼마나 수행하는가?
- Executor당 VCore와 Memory가 적당한가? → 실행 옵션

Spark의 캐쉬 지우기
| 메소드 | 의미 |
|---|---|
DataFrame.unpersist() | 각 노드의 캐쉬 사용을 모니터링하고 오래된 데이터를 LRU에 따라서 제거 |
RDD.unpersist() | 각 노드의 캐쉬 사용을 모니터링하고 오래된 데이터를 LRU에 따라서 제거 |
SqlContext.clearCache() | 모든 캐쉬 테이블 제거 |